
Optimizing Java Applications for Arm64 in the Cloud
Optimize Java applications for Arm64 cloud environments. Expert guide on JVM tuning, heap sizing, garbage collection, and maximizing Ampere CPU perfor...
Dave Neary3w ago
Optimize Java applications for Arm64 cloud environments. Expert guide on JVM tuning, heap sizing, garbage collection, and maximizing Ampere CPU perfor...

Discover the pros and cons of the top SEO tools of 2024. This article provides the essential details you need to choose. Continue reading Unleash Your...

Discover the 14 best SEO tools for agencies in 2025. Compare features, pricing, and usability to find the perfect solution for your clients and team....

Overview the top-tier Semrush competitors and learn how each platform can revamp your business with its tools, features, and unique offerings Continue...

Learn eight key steps for streamlining your technical SEO workflow to ensure that users and indexing bots get optimal access to your website. Continue...

A simple and detailed explanation of multi-head attention, showing how multiple attention heads help transformer models understand context and relatio...

Thanks to Meter for sponsoring this episode! Go to https://meter.com/craftcomputing to book a demo now! Wallets, Coffee Tumblers, Pint Glasses and mor...

This announcement is a recap from a post originally published on the Headlamp blog. Headlamp has come a long way in 2025. The project has continued to...

Configure and analyze NGINX access and error logs. Learn log formats, severity levels, troubleshooting, and integration with monitoring tools.

#608 — January 22, 2026 Read on the Web Node.js 25.4.0 (Current) Released — Another gradual step forward for Node with require(esm) now marked as sta...

The Rust team is happy to announce a new version of Rust, 1.93.0. Rust is a programming language empowering everyone to build reliable and efficient s...

Assess your disaster recovery architecture for secrets management with this guide for CIOs, CISOs, and cybersecurity decision-makers.
The community around Kubernetes includes a number of Special Interest Groups (SIGs) and Working Groups (WGs) facilitating discussions on important top...

Semantic HTML does a lot more accessibility work than we usually give it credit for already — and ARIA is simple to abuse when we use it both as a sho...

Thanks to Meter for sponsoring today's episode. If you're interested in learning more about how Meter can help with your IT Infrastructure, go to http...
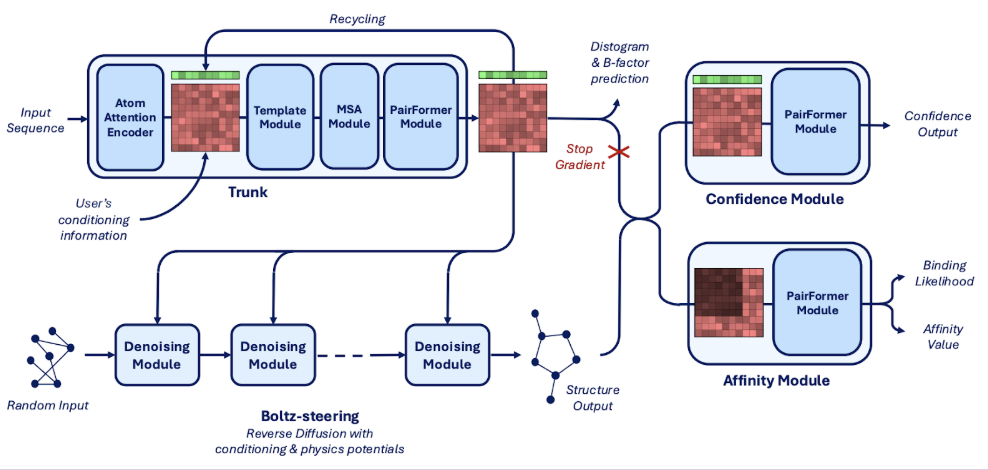
' In this article, we explore boltz-2 for predicting molecular binding affinity on DigitalOcean.'
A conversation between Unmesh Joshi , Rebecca Parsons , and Martin Fowler on how LLMs help us shape the abstractions in our software. We view our chal...

Learn how to integrate your Python projects with local models (LLMs) using Ollama for enhanced privacy and cost efficiency.

Check your understanding of using Ollama with Python to run local LLMs, generate text, chat, and call tools for private, offline apps.

FlashAttention 4 improves LLM inference with faster attention kernels, reduced memory overhead, and better scalability for large transformer models.
Showing 1321 - 1340 of 1985 articles